June 24, 2022
•
5
min read
There are some components you can’t imagine a big data environment without. Databases, processing units and data producers are core pieces of such platforms. Each reliable big data stack contains one more element - a message broker receiving data from producers and distributing it to further units.
If you use a cloud-based platform then your provider probably offers a messaging middleware solution, like GCP Pub/Sub or AWS SNS. In case of on-premise architectures you have to install and maintain such software by yourself. As the message broker is supposed to be a crucial part of the environment, you should look for some very reliable tool, that would preferably be open-sourced, broadly used and kept up-to-date. Here comes Apache Kafka - messaging platform developed by Apache Software Foundation, written in Scala (yay!) As you can read on Kafka’s official website the tool is open-sourced and “More than 80% of all Fortune 100 companies trust, and use Kafka”. Sounds like a perfect match, doesn’t it?
Let’s keep going with generally tried and tested solutions. Most of the nowadays software platforms are built as microservice architectures based on (Docker) containers, managed and orchestrated with a robust tool designed for such needs. Just like Apache Kafka is an absolute leader in message broker solutions, the containerized microservice platforms have their own hegemon — the Kubernetes. It’s open-sourced, created by Google and trusted world-wide, which makes it a very trendy choice.
Alright, so why am I making this introduction? Well, the importance and popularity of both Kafka and Kubernetes in the big data world should convince you that it’s worth knowing these tools and how to compose them into any data platform. If you want to build your own architecture running on Kubernetes, to play with some technologies and solutions, then you’d most probably want to have a Kafka instance there. This article shows how to set up such lightweight and transparent Kafka on your cluster.
Within this article we want to focus on instantiating Apache Kafka, and worry as little as possible on the Kubernetes cluster setup. In a real world scenario the cluster maintenance is usually driven by a dedicated DevOps team, and you as a data engineer, are provided with a fully operational Kubernetes platform. Therefore the solution presented here does not require any special Kubernetes configuration etc. You can run it on any available Kubernetes cluster. I also assume that you already have a very basic Kubernetes knowledge and you differentiate a pod from deployment and service, as well as you know how to use the [.code]kubectl[.code].
In case you don’t have access to any Kubernetes platform, we want to reproduce such seamless cluster obtaining here. One way to get such a Kubernetes instance, configured and working out of the box, is to use a fully managed platform offered by cloud providers, like GKE. However, such joy and simplicity comes with some significant costs that you’d like to avoid while setting up your very first big data platform, or testing some prototype solution. Here Minikube steps in — a local Kubernetes cluster, designed to learn and develop Kubernetes applications. You can install and start it with just a few commands, that will make you ready to proceed with our main goal — setting up the Apache Kafka.
As it has already been stated - Kafka is a very popular tool, applied in numerous big data environments. A basic instance of the Kafka can also be bootstrapped with just two components - a Zookeeper service for storing all the metadata, and a single process of Kafka broker. Hence, you could expect that step-by-step guide showing how to install it on a Kubernetes cluster (especially Minikube, as 99% of Kubernetes developers use Minikube) should be available in almost every corner of the Internet. That was also my assumption and I was pretty surprised, when after 15 minutes of a research I didn’t manage to have a working Kafka deployment using some Kubernetes manifests from the Web. Moreover, most of the examples I was able to find were using some custom Kafka Docker images - I am not a fan of such solutions, as such implementations can easily get outdated, additionally I always get cautious when working with containers from unknown author - at the first glance you never know what do they hide.
When looking for a Helm chart providing a deployment of the Kafka, the one that got my attention was created by Bitnami. However if our goal is to learn how a particular technology works, Helm charts tend to be too complex as for a toy instance of a given technology, as well as you may feel like using a black box when applying it - you just type a single command and a whole composition of pods, services etc. is there - that’s the Kubernetes’ magic. Therefore I decided to reject usage of the chart, as my main purpose was to get a solution that I fully understand and control.
If you can’t find some piece of code on Stack Overflow or in a Medium article with thousands of claps, it doesn’t mean that what you want to achieve is impossible. Even though my research ended with a failure, I did not give up and decided to develop the solution I was looking for by myself. In fact, composing it was almost as quick, as the foregoing efforts.
My starting point was the docker-compose provided by Confluent - one of the largest Apache Kafka enterprise vendors. As the whole Confluent Platform is built with Kafka in the core, I had no doubt, that presented solution is a reliable one:
The definitions of images seem pretty straightforward, with as little configuration as possible. Meaning of all the environment variables for broker image can easily be translated into values from Kafka’s broker configuration. Hence, we can carelessly use this compose to create our Kubernetes manifests.
Let’s start with translating the Zookeeper part of the docker-compose to a Kubernetes deployment named [.code]zookeeper[.code]. If you are not familiar with the deployment’s file structure you can refer to an example from the official documentation and just rename the configuration values. With just two environment variables, specifying the [.code]tickTime[.code] and [.code]clientPort[.code] values (you can read about them in Zookeeper quickstart) the corresponding Deployment manifest looks like:
We specified here [.code]containerPort: 2181[.code] as we want our Kafka to communicate with the Zookeeper using this port. To make the Zookeeper easily reachable within the Kubernetes cluster we should add a Service definition — we may place it in the same YAML file, just below the Deployment’s part:
and the response shows, that our very first resources have been created:

After few seconds the Zookeeper pod should be created:

You can also check the pod’s log messages with [.code]kubectl logs -f <POD_NAME>[.code] command to ensure, that the service is working properly:
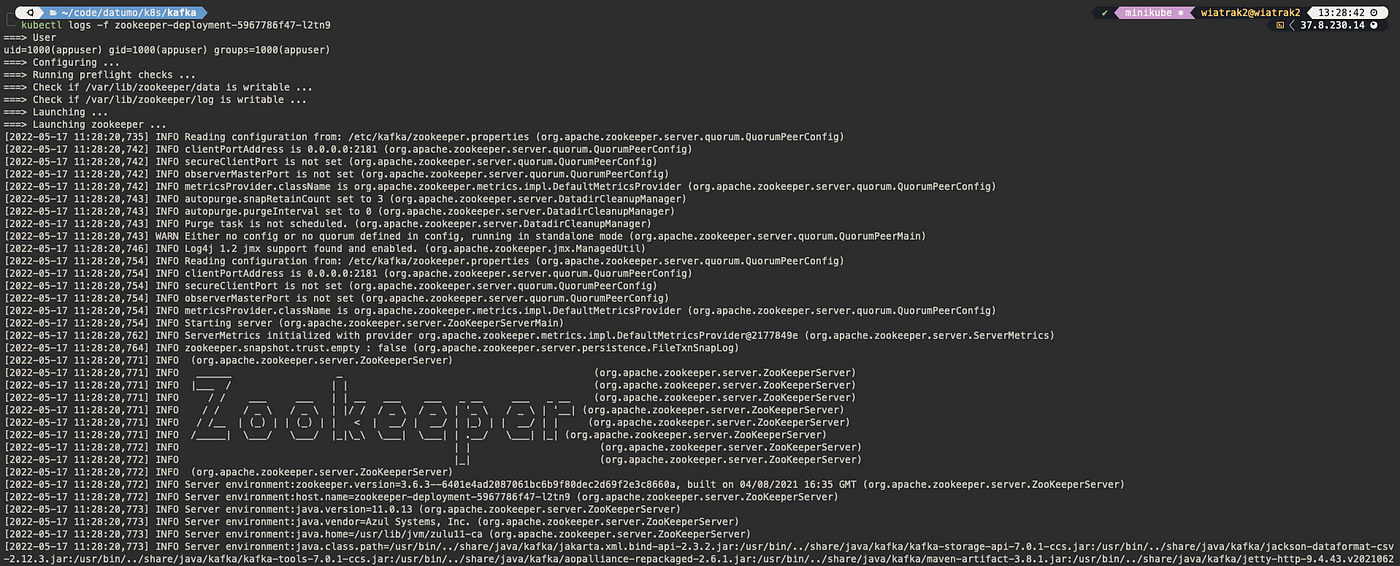
Perfect! The only thing left is now to configure and create the Kafka broker based on the Confluent’s docker-compose. Let’s have a look at the specified environment variables - [.code]KAFKA_BROKER_ID[.code] seems like nothing we should worry about. The KAFKA_ZOOKEEPER_CONNECT specifies how a broker can reach the Zookeeper - we want this value to point at the Kubernetes service we’ve just created, therefore we should set it as zookeeper-service:2181. The [.code]KAFKA_OFFESTS_TOPIC_REPLICATION_FACTOR, KAFKA_TRANSACTION_STATE_LOG_MIN_ISR[.code] and [.code]KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR[.code] values can be left unchanged, as they determine messages storing policy.
In fact, the [.code]KAFKA_ADVERTISED_LISTENERS[.code] configuration value is the only one we should worry about. The advertised.listeners is used to tell the clients (data producers and consumers communicating with your Kafka instance) how to connect to brokers. There is a great article (on Confluent website) explaining the listeners configuration - I strongly encourage you to read it. When setting the advertised.listeners value, we need to consider that it must tell the broker itself, how it is reachable, and allow external services to connect with the broker. Therefore we need two values here - just like it is specified in the docker-compose.
To specify the “internal” communication we will use PLAINTEXT://:29092 listener (empty hostname is equivalent to the localhost, but we don’t like to use this word in our configurations, do we?). The listener used outside the broker pod can be specified as [.code]PLAINTEXT_INTERNAL://<SERVICE_NAME>:<SERVICE_PORT>[.code](let’s keep the convention from the docker-compose and use [.code]PLAINTEXT_INTERNAL[.code] as the name of the listener reachable outside the container). To make the implementation better structured you could use a Kubernetes ConfigMap resource that would store values for environment variables, however for now we can just hardcode them and set the service address to kafka-service and 9092 port, and write it down in the env section, so we minimize the number of files 😉. Hence, our value for [.code]KAFKA_ADVERTISED_LISTENERS[.code] would be [.code]PLAINTEXT://:29092,PLAINTEXT_INTERNAL:9092[.code]. As already stated - we need to attach a Kubernetes service definition, exposing the [.code]9092[.code] port, so the broker is reachable from the cluster. Therefore, the entire Kubernetes manifest configuring our Kafka broker can look like:
And that’s it, really. Let’s create our resources with kubectl apply. After few seconds our Kafka broker pod will start it’s life next to the Zookeeper one.
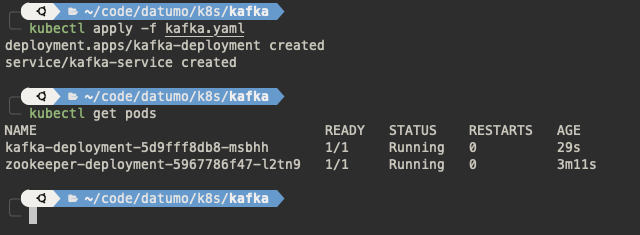
If you look into the pod’s logs you could note that the broker will register itself and resolve it’s in-cluster hostname:

Well, congratulations - your reliable and clear Kafka instance is ready to use! 🎉
To finish our job we need to confirm that our broker is indeed reachable from the Kubernetes cluster, and ready to be our 100% valid message broker. Firstly let’s create our first Kafka topic - we need to get into the broker pod with [.code]kubectl exec -it <POD_NAME> —- /bin/bash[.code] command and use kafka-topics binary to create one (let’s name it minikube-topic). Further, with kafka-console-consumer utility we can get into consumer mode and wait for incoming messages:
Now it’s time to send some messages to our brand new Kafka topic. We could for instance use kafka-console-produce utility, but let’s do it in a bit more fancy way and create a Python-based producer, which most probably reflects how you will produce the messages across your platform. In a new terminal with the kubectl run command, we can create a pod running a Python image, with [.code]stdin[.code] and [.code]TTY[.code] allocated (for det). Use bash as a command to install extra packages before jumping into Python REPL.
To interact with Kafka we will use confluent-kafka client library - there are many other possibilities, but this package is kept up-to-date, well documented and we already like Kafka utilities provided by Confluent. Once the package is installed we can start the Python REPL and create a Producer object - just follow the docs. Use [.code]kafka-service:9092[.code] (our broker’s address) as bootstrap.servers value. With the producer instantiated we can then send a first message to our Kafka minikube-topic topic.
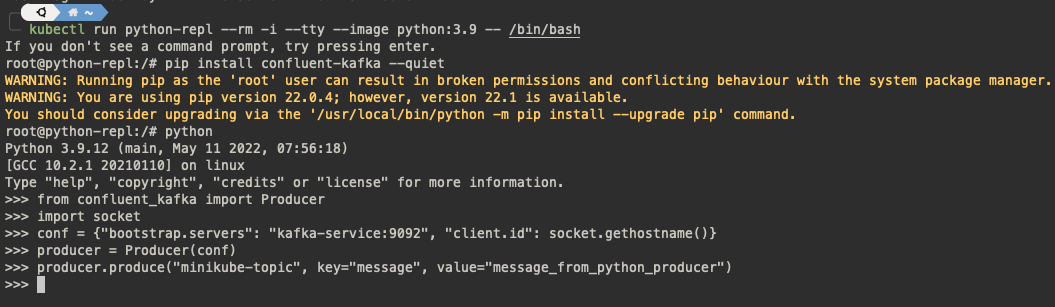
After that we can go back to the terminal with kafka-console-consumer process running. And here’s the sign of the success - we can see that the message sent from the Python producer was received and well processed.

There is one things you could already do to make the deployment more reliable - you can ensure, that the created pods won’t consume too much resources from your cluster by setting the limits in containers’ specification. The restriction level should depend on your cluster’s capability and importance of the services. If you use Minikube on your local PC you have few cores and gigabytes of memory that need to be sufficient not only for all Kubernetes resources you want to create, but also for other quite heavy processes running on the computer, like the browser you use to read this article. When running Kubernetes on a dedicated cluster, you can afford more resources, as you have power of multiple machines, intended to only execute Kubernetes processes, on your command. Additionally, if Kafka is going to be a background service in your environment, you’d prefer to left as much computational power as possible for your main components, but if you deploy Kafka to explore it’s possibilities and test it to the limit - you should allow it to consume more.
To set the resources limit add resource section to your manifest. For instance, if you’d like your Zookeeper to use no more than 128 MiB of memory and 0.25 of CPU add following definition e.g. under the env part:
Note, that the limits are applied to a single container, hence if your deployment create multiple pods, each of them will allocate such part of your resources. You should also restrict the resources consumption for Kafka’s pod, e.g. up to 512 MiB and 0.5 CPU for each broker (we use a single one here):
After this exciting journey we can clearly say that creating a basic Kafka deployment is a piece of cake. All you need is a Kubernetes cluster, even Minikube, without any complex configuration, and two simple Kubernetes manifests presented in the article. With those two YAML files you can in no time bootstrap your Apache Kafka instance, using Confluent’s official Docker images and with minimal configuration required. Now you are ready to extend your platform and conquer the big data world! ⚔️

Get to know us, discover our interests, projects and training courses.
.png)

.png)


.png)
