November 20, 2023
•
5
min read

“Hey, I have a problem with your transformation producing table/report X - for customer user123 the value should be 42, but we get a NULL - can you check that?” If you are a data engineer, you’ve probably heard such questions hundreds of times. And you begin to dread these innocent testers and analysts raising their issues, as you know what’s knocking on your door - painstaking analysis of your code and data. Unexpected results from a Spark application are inevitable. Finding the root cause requires a lot of dirty, manual debugging. You need to put everything else aside and go through the transformations to eventually figure out that there is an inner join between two DataFrames that removes the record you are tracking. And, to crown it all, in the end you realize that everything is in order, the entire bug should never be raised and your precious time has just been wasted.
Tracking the transformations applied to a particular record(s) in an Apache Spark application is a huge challenge. Spark jobs are designed to process huge amounts of data by applying multiple transformations to whole datasets simultaneously. However, even in the big data world, it’s sometimes necessary to limit the universe to a single record. There are a few common approaches to investigate how a particular data entry may get changed within an execution, but they usually are neither effective nor reliable.
A typical Apache Spark data processing application loads its input data from tables stored in a warehouse like Delta Lake, Apache Hive or Google BigQuery. The data is packed into DataFrame or Dataset structures and numerous transformations (and actions) are applied to them, resulting in final DataFrames/Datasets, that are eventually saved as new tables (ETL jobs) or exported as reports with a business value. There are a few debugging Spark application approaches to track how a single row changes through the execution, however none of them are convenient nor reliable. One solution is to reproduce the implemented transformations as SQL queries. You may imitate every function in your code in subsequent CTEs/queries, and filter the results at each step to see the output for the record you track. Translating a Spark code to SQL is an arduous task, especially if Spark UDFs or features like the .map() function on Dataset are used - a single line of Python/Scala code may require multiple complex clauses to reproduce it in SQL. Moreover, even though every Spark transformation can be translated into an equivalent SQL query, it’s easy to make a mistake leading to an incorrect investigation.
If you are lucky enough to operate on an environment like Databricks which provides Python/Scala notebooks, you may copy and paste the code of your application to such an interactive tool. You could then add debug messages like df.filter($”customer_id” === “user123”).show() between the transformations to output DataFrames/Datasets content for the value you need to track. These Spark logs would subsequently present the changes to your record through the application. However, it might be difficult or even impossible to run the notebook - first of all, you’d need to have sufficient permissions to execute a code on your cluster, which is usually disabled for production environments. Your application may also refer to some internal packages and modules to import classes and functions - providing these dependencies for a notebook is not usually a straightforward task.
The possibility of inserting debug messages in the application’s code sounds like a very promising approach to investigate your record changes. However, such lines of code obviously wouldn’t survive the PR review process - the code you deliver needs to be as clean and effective as possible. Such an approach seems to be a solution for the majority of data investigation problems, but it can’t be provided without having devastating effects on your application. And that’s where dataset-logger comes in.
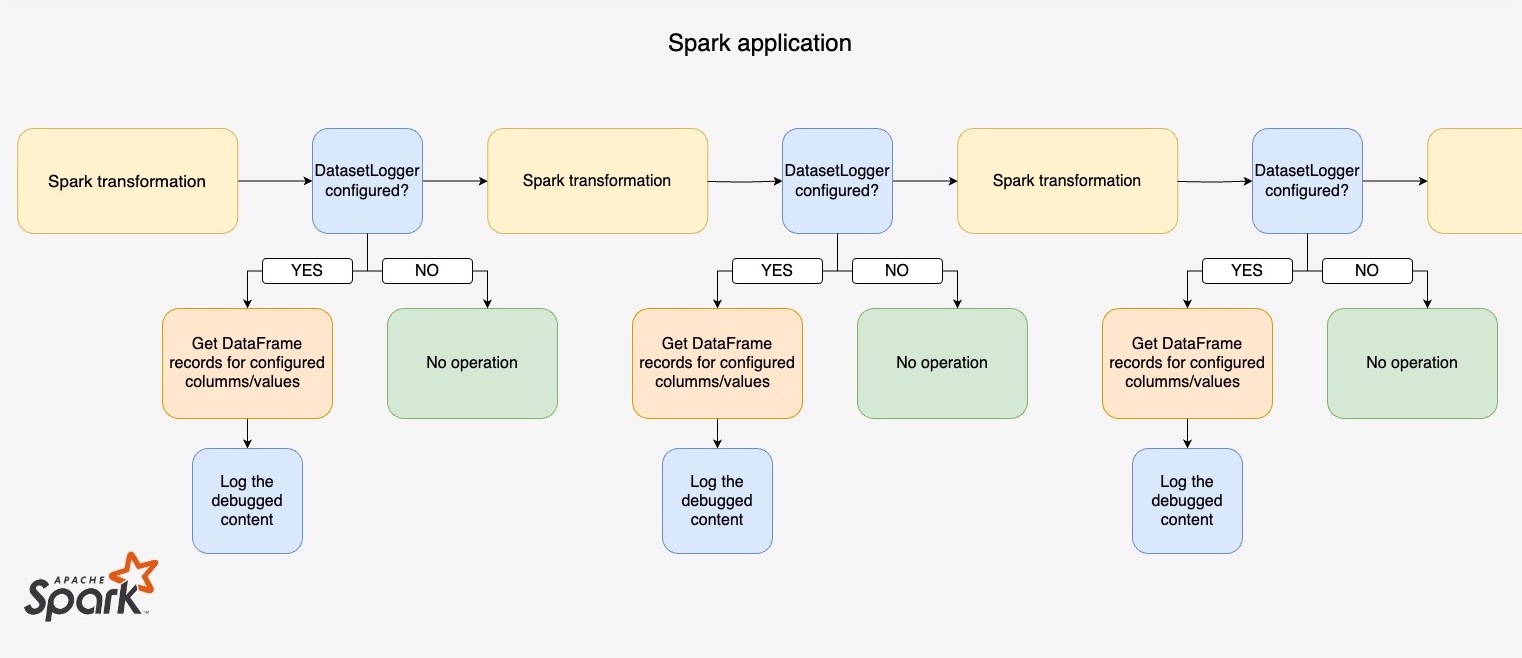
dataset-logger is a Scala package designed to provide that exact option to you - to produce log messages with a DataFrame/Dataset content during your Spark application execution. Most importantly - it neither affects your Spark job performance, nor requires any dedicated code changes to obtain insights for a particular record. The tool was implemented in a way that allows you to introduce it to your highly-effective, production-adjusted code. The most important aspects and goals during dataset-logger development that make it stand out from other debugging tools are:
More implementation details on how we managed to fulfill these expectations can be found in dataset-logger’s git repository. Now let’s have a look at how to save time and effort when investigating data transformations for a single record.
dataset-logger Scala package is published to the maven central repository for both Scala 2.12 and 2.13. You can include it in your Scala project as a regular dependency with sbt or maven. See installation section in the repository.
The main facility of the dataset-logger package is a class named… DatasetLogger (surprisingly) that provides the option of producing clear and valuable Spark logs with DataFrame/Dataset content. The DatasetLogger class takes a single constructor parameter - a String or Option[String] with configuration in JSON format. A very basic, but sufficient configuration looks like:
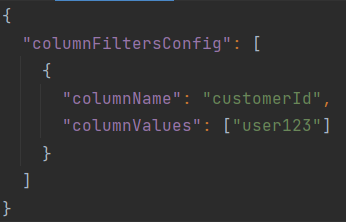
When invoked, it specifies to monitor and debug DataFrame/Dataset records with customerId column value equal to ”user123”.
When implementing Spark applications in Scala it’s quite common practice to create a dedicated class for each Spark job. Such a class is usually parametrized with some configuration values specifying the context of a singular run, like date or country for which the computations are supposed to be executed. The class may also extend some Scala traits providing common functionalities and methods specific to the organization.
As DatasetLogger is a Scala class, you can introduce it to your code in two ways: either by inheriting DatasetLogger by your job’s class, or by creating a DatasetLogger instance in its definition. In both cases the String/Option[String] with JSON configuration needs to be passed to the DatasetLogger constructor. Let’s say, like myself, you prefer the first option, and you extend your MySparkJob(jobParams: JobParams) class with DatasetLogger. For convenience we assume that MySparkJob is initialized with JobParams case class, which contains arguments passed on from the application launch e.g. from the command line.
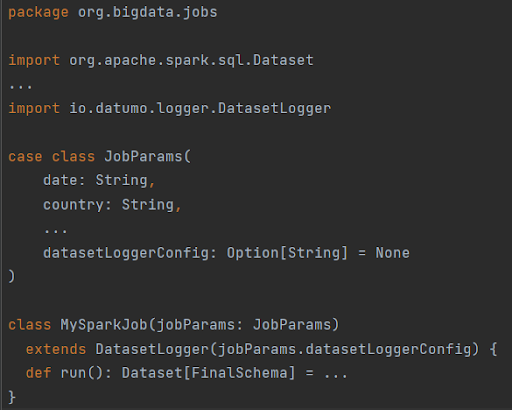
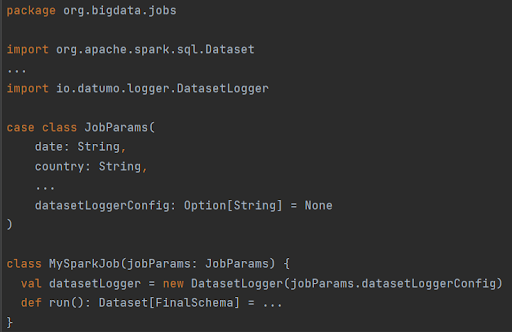
Hence, to introduce DatasetLogger to your codebase, you should just inherit/instantiate the class and add a new parameter in JobParams, let’s say datasetLoggerConfig: Option[String] = None (like in code snippets above) that would contain the JSON configuration if passed. When DatasetLogger is initialized with an empty String or None, it omits all the computations whenever the code refers to its methods, ensuring that there’s no impact on your job’s performance during a regular execution without datasetLoggerConfig specified.
Alright, you have your DatasetLogger configured and armed (or disabled if not needed), now it’s time to quickly adjust the MySparkJob implementation. Let’s assume that it computes a sequence of Spark transformations like:
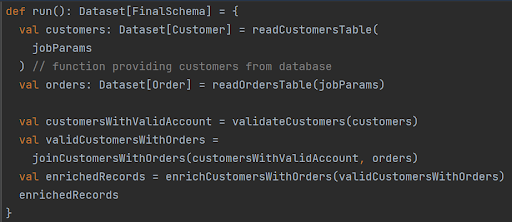
How to modify this code to gain the option of investigating each of the constructed Datasets with minimal changes? Just use DatasetLogger method called logDataset that combines a Dataset with JSON configuration to obtain the desired records. It’s also a good idea to invoke logDataset inside logger.debug() function (where logger is a logging utility constructed with the e.g. scala-logging package) to ensure the messages are written to the proper output when log level is set to DEBUG:
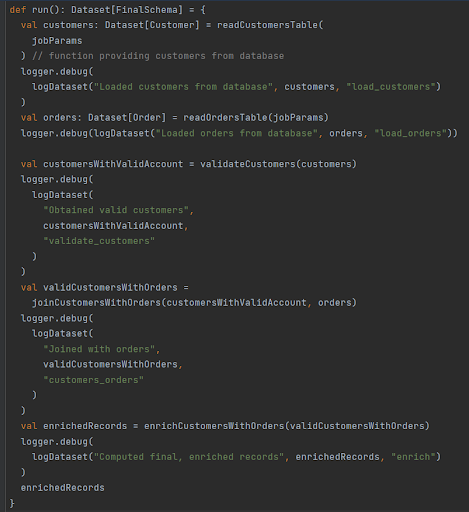
and that’s it - we just added log messages with the logDataset method called inside. Sometimes you don’t even have to add any new lines, as you could already have some debug log messages (e.g. with .count() values printed) and all you need to do is encapsulate it with logDataset. Invocations added between each transformation make them work like breakpoints.
The presented approach uses DatasetLogger class inheritance. Another solution could be instantiating it like val datasetLogger = new DatasetLogger(...) and constructing log messages with datasetLogger.logDataset(...) (as shown in the earlier snippet). Both options fortify your Spark application with the remarkable ability to produce highly valuable Spark logs with DataFrame/Dataset content.
After adjusting your code with these minimal changes you may deploy the new version of your application and benefit from DatasetLogger functionality. Whenever you need to investigate a particular column(s), just provide the configuration like the one shown above to your Scala application execution. You can ship such JSON in various ways - by passing it as an extra command line argument, by specifying a path to a file containing it etc. - select the solution most convenient to your implementation.
With the basic configuration presented previously and setting the level of logged messages to debug (which should be at least info by default) for a MySparkJob execution, the logger.debug(logDataset(...)) calls will be triggered. The provided configuration will produce messages with Datasets content equivalent to dataset.filter(col(“customerId”).isin([“user123”])).show(), for each of the Datasets passed to logDataset as second arguments - the first being a log message, the third, an identifier of each logDataset call, so you can specify some dedicated behavior for individual invocation.
Application execution triggering DatasetLogger features, has an inevitable impact on its performance and running time - Spark actions collecting the DataFrame/Dataset content must add their burden to get the desired results. It’s worth mentioning that DatasetLogger takes care of persisting the passed DataFrame/Dataset by default and you can customize the storage level or even disable this caching with appropriate config values.


Note that both JSON configuration and logDataset reference may have additional parameters that increase the logging options with features including handling renamed columns, defining SQL queries for entire debugged DataFrame/Dataset, skipping logDataset invocations not relevant for particular executions. All the possible parameters and functionalities are described in the dataset-logger repository.
Alright, we’ve introduced the dataset-logger features to MySparkJob for a reason. What does the produced output look like? Let’s have a look at a file/stream with log messages. After the application execution you should be able to find a block of driver logs for each logDataset call:
[DatasetLogger] Loaded customers from database
[DatasetLogger] ----------------
[DatasetLogger][customers] Dataset contains 1 matching rows:
[DatasetLogger] ----------------
[DatasetLogger] | customerId -> user123 | name -> Bilbo Baggins | age -> 111 | country -> Shire |
…
[DatasetLogger] Joined with orders
[DatasetLogger] ----------------
[DatasetLogger][customers_orders] Dataset contains 3 matching rows:
[DatasetLogger] ----------------
[DatasetLogger] | customerId -> user123 | name -> Bilbo Baggins | age -> 111 | country -> Shire | orderId -> o17 | itemId -> i22 | itemName -> Ring | itemQuantity -> 1 | itemPrice -> 42.42
[DatasetLogger] | customerId -> user123 | name -> Bilbo Baggins | age -> 111 | country -> Shire | orderId -> o17 | itemId -> i96 | itemName -> Sword | itemQuantity -> 1 | itemPrice -> 13.99
[DatasetLogger] | customerId -> user123 | name -> Bilbo Baggins | age -> 111 | country -> Shire | orderId -> o18 | itemId -> i121 | itemName -> Beer | itemQuantity -> 3 | itemPrice -> 2.0
…
example of driver log messages produced by DatasetLogger configured to track user with value user123 in customerId column
That’s awesome! Thanks to introducing the dataset-logger package to your project, you can literally track particular record(s) flowing through any Spark application and present their changes at each step of this journey. This fantastic option has no impact on the regular execution of the Spark job, doesn’t deface your code and waits idle until you need it for another specific data investigation. Therefore, whenever your colleague asks you to debug what has happened with another suspicious record, all you have to do is execute the application again with DatasetLogger configuration applied. You can stay focused on the important part of your daily duties, while DatasetLogger finds the answer you are looking for. If the demonstrated example is not transparent enough, you can check a more detailed one with holistic implementation provided in the dataset-logger examples.
The described process presents the dreaded problem space of a particular record(s) transformations investigation, that is addressed by the dataset-logger package. Minimal code changes and basic, easy to provide configurations, allows you to overcome significant limitations and restrictions of a typical Spark code deployed on production, and track how your data is changed throughout its execution. The features implemented in dataset-logger make debugging Spark applications much easier and allows the entire data platform community to save time and energy. We have successfully introduced dataset-logger to multiple organizations and the package has proved invaluable and has had a hugely beneficial impact on data platforms and their users.
Once again I’d like to encourage you to check the Github repository of dataset-logger and incorporate the package to your Apache Spark project. We’d love to hear your feedback about the tool. In case of any questions or doubts, feel free to contact us!

Get to know us, discover our interests, projects and training courses.
.png)


.png)

.png)